1) Flask
- Flask와 연결하기
import pymongo
from bson import ObjectId
import csv # 일반적으로 필요하진 않음
from flask import Flask, render_template, request, redirect
app = Flask(__name__)
client = pymongo.MongoClient('localhost', 27017) # 클라이언트 연결
db= client.get_database("MyDB") # 전역변수 설정
col = db.get_collection("post") # 전역변수 설정Flask와 연결하기 위해서는 flask 모듈들을 임포트 해주어야한다.
연결 후, MongoDB와 html을 이용해 글 목록 조회, 작성, 생성, 읽기 페이지를 만들어보자.
아래부터 python 코드와 html 코드를 같이 봐주면 된다.
- 글 목록 보기
@app.route("/", methods=['GET'])
def index(): # 이름은 마음대로
documents = col.find()
return render_template('index.html', documents=documents)
# html 파일에 정보를 넘겨준다.
!-- index.html -->
{% for doc in documents %} <!-- python파일의 documents를 불러옴-->
<li><a href="/post/{{doc._id}}">{{doc.title}}</a></li>
{% endfor%}
- 글 작성하기
@app.route("/new") def new(): return render_template('main.html')
url이 /new 인 페이지에 main.html 파일을 불러온다.
글을 작성하는 페이지에서 보여줄 정보는 없으므로 다른 코드는 필요 없다.
<!-- main.html -->
<h2>Add a Post</h2>
<form action="/create" method="POST">
<table>
<tr><td>Title: </td><td><input name="title"></td></tr>
<tr><td>Content: </td><td><input name="content"></td></tr>
</table>
</form>제목과 내용을 적어 제출 버튼을 누르면 정보가 전송이 되는 form이다.
action="/create"를 통해 /create 페이지로 POST한다.
- 글 생성하기
@app.route("/create", methods=['POST'])
def save():
data = {"title": request.form['title'],
"content": request.form['content']}
res = col.insert_one(data)
return redirect(f"/post/{res.inserted_id}") # redirect를 통해 url이 /post인 글읽기 페이지로 바로 이동url이 /create인 페이지니까 앞전에 글 작성하기를 통해 작성된 글이 이곳에서 생성된다.
data = request.form['title'] 을 통해 정보를 넘겨받는다.
col.insert_one(data) 를 통해 정보를 삽입한다.
res.inserted_id 를 통해 전달받은 정보의 id값을 불러온다.
- 글 읽기
@app.route("/post/<_id>", methods=['GET'])
def show(_id):
post = col.find({ "_id": ObjectId(_id) })[0]
return render_template('show.html', post=post)글 정보를 가져오기 위해 _id를 가져오는데, 반드시 ObjectId(_id)로 불러와야한다.
도큐먼트에 저장된 형식이 그렇기 때문이다.
post 라는 변수에 저장시킨다.
<!-- show.html -->
<h2>{{ post.title}}</h2>
_id: {{ post._id}}<br>
Content: {{ post.content}}<br>post.title, post._id 를 사용해 정보를 출력한다.
2) 세 가지 집계 방법
전 포스팅에서 배운 find 명령어는 평균, 분포 등 집계와 관련된 내용을 수행하지 못한다.
도큐먼트를 집계하는 방법은 세 가지가 있다.
- DB 정보를 불러와 애플리케이션 단계에서 집계- Python 코드를 이용하여 원하는대로 정보를 조작함
- MongoDB의 맵-리듀스 기능
- MongoDB의 집계 파이프라인 기능
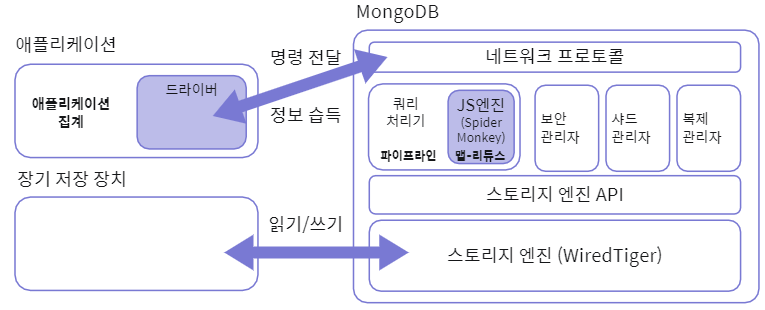
맵-리듀스 기능을 사용할 때는 JS엔진에서 처리하고
파이프라인 기능을 사용할 때는 MongoDB 내부의 쿼리처리기에서 처리한다.
반면에 애플리케이션에서 처리할 때는 MongoDB 바깥의 앱 내부에서 처리한다.
처리속도: 애플리케이션 < 맵-리듀스 < 집계 파이프라인
자유도: 애플리케이션 > 맵-리듀스 > 집계 파이프라인
- 맵-리듀스
맵핑 함수: 관련된 정보끼리 그룹화
리듀스 함수: 그룹 내 정보들을 집계 연산

위 예시는 동물의 종류에 대해 그룹으로 묶고, 그 그룹 내의 값의 수를 집계한 것이다.
- 집계 파이프라인
한 데이터 처리 단계의 출력이 다음 단계의 입력으로 연결된 구조

집계 파이프라인의 스테이지에 따라서 정보들을 순차적으로 처리한다.
메모리, 속도 측면에선 효율적이다.
3) 인덱스 개요
인덱스는 신문을 제목과 분류별로 정리하는 것처럼 검색과 순서 정렬을 효율적으로 만들어준다
만약, 인덱스가 없다면 모든 도큐먼트를 일일이 조회해야 한다.
따라서 인덱스는 쿼리 작업을 매우 효율적으로 만든다.
하지만 인덱스를 업데이트해야 하기 때문에 약간의 속도 저하는 있다.
- 단순 인덱스: 하나의 필드를 기준으로 생성한 인덱스
- 복합 인덱스: 다수의 필드를 기준으로 생성한 인덱스

4) 복제 세트
같은 정보를 공유하는 Data Set이다.
높은 가용성과 정보의 안전한 보호를 위해 복제를 한다.
- 복제 세트의 구성원
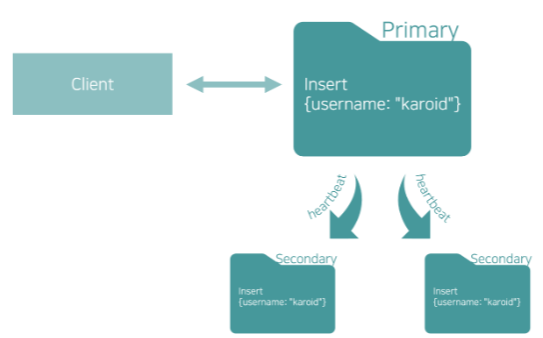
복제 세트는 프라이머리, 세컨더리, 아비터 로 이루어져있다.
Heartbeat 를 통해 구성원끼리 생존상태를 확인한다.
프라이머리: 클라이언트로부터 직접적으로 RW 요청 수행. (삭제, 수정 등 수행)
세컨더리: 프라이머리가 하는 행위를 따라하여 정보를 갱신
아비터: 정보를 갖진 않고, Heartbeat를 통해 서로의 상태를 확인
- 복제 세트의 선거
프라이머리가 죽게 되면, 복제 세트 구성원 중 과반수의 세컨더리가 이를 감지하여
'선거'를 개최
선거란, 세컨더리 중 하나를 프라이머리로 지정하는 과정을 수행
투표 중, 가장 최신의 정보를 가진 세컨더리가 선발된다.
클라이언트와 프라이머리의 연결이 끊겨도, 이 선거를 통해
새로운 프라이머리(전 세컨더리)와 금방 연결이 가능하다.
- 복제 세트의 장점

세컨더리를 활용해 읽기 기능이 확장 가능하다. (쓰기는 불가능)
따라서, 프라이머리의 읽기 부하를 줄일 수 있지만 읽기 지연은 생긴다.
5) Read-Concern과 Wirte-Concern
Read-Concern: 어느 정도 동기화 수준을 기준으로 정보를 읽어올지 설정
Write-Concern: 어느 정도 동기화 수준을 기준으로 쓰기 작업을 마무리할지 설정
복제 세트에서 구성원의 정보가 동기화되면 데에는 시간이 필요하기 때문에 필요
예를 들어, 글을 작성했을 때 바로 작업을 마무리할지 아니면
글을 작성하고 제대로 작성됐는지 확인이 되면 작업을 마무리할지 결정하는 게
Write-Concern이다. Read-Concern도 마찬가지(읽기에 대해)
- Read-Concern과 Write-Concern 설정 방법
import pymongo
from pymongo.write_concern import WriteConcern
from pymongo.read_concern import ReadConcern
client = pymongo.MongoClient('localhost', 27017)
db= client.get_database("myDB")
rc= ReadConcern(level='majority')
wc= WriteConcern(w=1, wtimeout=200, j=True)
col = db.get_collection("post", write_concern=wc, read_concern=rc)from pymongo.write_concern import WriteConcern >> WriteConcern 객체를 불러옴
from pymongo.read_concern import ReadConcern >> ReadConcern 객체를 불러옴
rc = ReadConcern(level='majority') >> ReadConcern의 옵션 설정
wc = WriteConcern(w=1, wtimeout=200, j=True) >> WriteConcern의 옵션 설정
위 코드 마지막 줄을 보면 collection인 col에 설정하였다.
컬렉션이 아닌 클라이언트나 DB에도 설정이 가능하다.
- Read-Concern 설정
rc = ReadConcern(level='majority')
local: 연결된 인스턴스(세컨더리 등)에서만 정보를 불러옴
majority: 복제 세트 대다수에 저장된 정보로 불러옴
linearizable: 시간 제한 내에 복제 세트 구성원의 정보를 확인해서 대다수에 저장된 정보로 불러옴
- Write-Concern 설정
Write-Concern 옵션에 대해 알기 전에 저널링을 알아야한다.

저널링이란? 디스크에 변경사항을 임시로 저장하는 작업으로
메모리에서 장기 저장 장치로 저장할 때 사용하는 임시 저장 기술이다.
wc = WriteConcern(w=1, wtimeout=200, j=True)
w: 복제세트의 어느 정도의 구성원에 쓰기 작업이 완료돼야 전체 쓰기 작업이 완료 됐다고 판단할지
결정하는 옵션으로, 숫자나 문자열로 지정
j: 이 옵션이 true값을 가지면 변경 사항을 바로 저널링해서 장애가 발생하더라도 문제가 없게 함
기본값은 false
wtimeout: w 옵션에서 설정한 구성원들을 기다릴 수 있는 최대시간(ms).
주어진 시간이 지나도 정해진 구성원에 쓰기 작업이 마무리되지 않으면 에러를 반환.
쓰기 작업이 무한정 지연되는 것을 막기 위한 옵션으로, w 값이 1보다 커야 사용 가능
- w 옵션
| 0 | 쓰기 작업이 실제로 수행됐는지 확인하지 않고 작업 완료 |
| 1 | 클라이언트와 연결된 인스턴스의 쓰기 작업을 수행하면 작업 완료 |
| 1보다 큰 자연수 | 값으로 갖는 숫자가 복제 세트에서 쓰기 작업을 완료한 구성원 수와 같으면 작업 완료. 예를 들어 w:2로 설정되었다면, 1개의 프라이머리와 1개의 세컨더리에서 쓰기 작업이 실행되면 작업 완료. |
| majority | 복제 세트에서 대다수의 구성원이 쓰기 작업을 완료하면 작업 완료. |
5) 샤드 클러스터
컴퓨터의 모든 장비는 고성능이 될 수록 가성비가 안 좋아진다.
성능이 2배 좋은 서버보다 2개의 서버를 쓰는 게 경제적이다.
이럴 때 필요한 것이 샤드 클러스터이다.
- 샤드 클러스터의 구성

App Server: 사용자
Config Servers: 클러스터의 설정값과 샤드의 메타데이터 보유.
앱 서버에서 요청이 들어오면 샤드로 신호를 보낸다.
Shard: 분산된 정보를 가지고 있다.
- 샤드 클러스터 작동 방식

1) 애플리케이션과 드라이버가 읽기/쓰기 요청을 보낸다.
2) 라우터가 요청을 받는다.
3) 라우터가 각각의 샤드에 요청을 보낸다.
- 샤딩의 기준
샤드에 정보가 골고루 분산되어 연산이 골고루 이루어져야 한다.
이럴 때 쓰이는 샤딩의 기준은 세가지가 있다.
(1) 범위 샤딩: MongoDB가 범위에 따라 분산하여 범위 조회 시 유리하다.
하지만 특정 범위에 도큐먼트가 쏠리면 해당 샤드만 계속 바빠질 수 있다.
>> 예를 들어, 사람의 키를 범위로 나누어 저장하면 평균에 해당되는 수치
즉, 165~175cm에 해당하는 키는 한 샤드에 쏠려 저장이 된다. 이럴 때는 그 키가 포함된 샤드만 계속 바쁠 수 있다.
(2) 해시 샤딩: 샤드의 키 값을 Hash Function에 집어 넣는다.

이 경우는, 도큐먼트가 골고루 저장되어 몰릴 가능성이 낮다.
하지만, 범위를 찾는 쿼리를 수행할 때는 다수의 클러스터에서 찾아야한다.
(3) 구역 샤딩: 개발자가 구역을 지정해서 분배하는 방식이다.
손이 많이 가지만 최적화된 샤드 구성이 가능하다.
'Backend > MongoDB' 카테고리의 다른 글
| Mongoose ODM 기초와 간단한 CRUD 구현 코드(Node.js) (0) | 2022.02.26 |
|---|---|
| MongoDB - 연산자 (0) | 2022.02.02 |
| MongoDB - CRUD (0) | 2022.02.01 |
| MongoDB 개요 (0) | 2022.02.01 |